はじめに
データベースの設計は基本設計の中でもかなり重要な工程です。
特にデータの構造によってアプリケーションが決まるため、データベース設計での失敗をアプリケーションで改善することはできません。
今回は『達人に学ぶDB設計徹底指南書』で指摘されているアンチパターンをピックアップして紹介します。
アンチパターン
非スカラ値の格納(第一正規形未満)
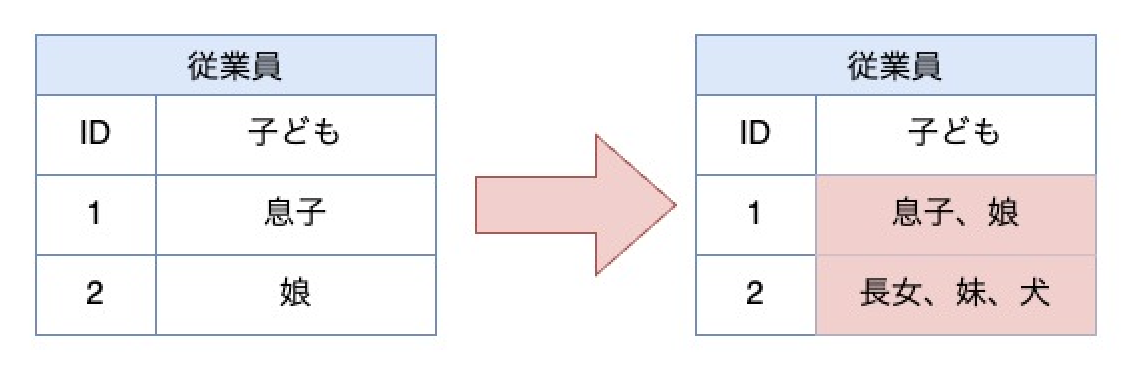
【症状】
第一正規形はデータベースの原則である、テーブルに含まれるすべての値がスカラ値であるという原則を無視した「複数の値」をセルにいれること
【なぜ起こるか?】
開発者がRDBに柔軟なデータ型が欲しくなり、実装してしまった…など
【問題点】
- 正規化の原則に則っていない。
- 検索性能の悪化、該当のカラムによるjoinができない。
- アプリ側の処理が複雑化する。
【対策】
- 正規化をしっかりと行う
- 多対多の関係を表現する場合は中間テーブルで設計する
ダブルミーニング
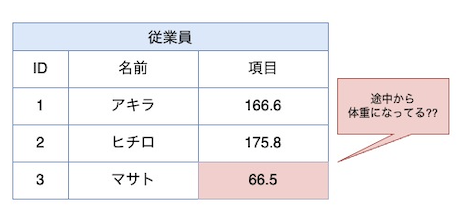
【症状】
value カラムには「身長」と「体重」の両方入っている
【なぜ起こるか?】
途中からvalueカラム(身長)が不要となり、「体重」が必要となったため、列の使い回ししたくなった…など
【問題点】
- 前提としてテーブルの列は変数ではなく、静的で固定的なものなので一度決めたら容易に変更してはいけない。
- 意味の解釈が曖昧になってしまい、システムのバグを生む原因となる。
- コーディングに余計な注意を払わなければいけなくなり、運用・開発効率が下がる。
【対策】
- 正規化をしっかりと行う
- 多対多の関係を表現する場合は中間テーブルで設計する
単一参照テーブル
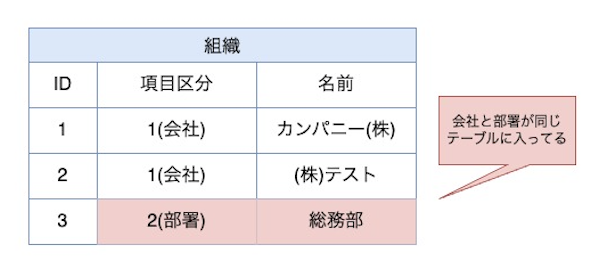
【症状】
部署や会社といった別の意味を持つものを構造的に似ているということで一つのテーブルにまとめてしまう。
【なぜ起こるか?】
数百テーブルがある状況において、同じ構造を持ったテーブルを一つのテーブルにまとめることで効率化を図った…など
【問題点】
- 特定のカラムを複数の意味で使い回すため、大きめの可変長文字列で宣言する必要がある。(パフォーマンスの劣化)
- 検索用SQLのロジックが間違えていてもエラーにならないため、バグに気づきにくい。
- ER図のオブジェクトは減るが可読性が下がる。
【対策】
- 用途ごとに明確なテーブルを作成すること
テーブル分割
水平分割
【症状】
レコード単位でテーブルを分割してしまうこと
例えば2010年用のテーブルと2011年用のテーブルなど、、、業務系のトランザクションテーブルに多い
【なぜ起こるか?】
何百万〜何十億とレコードが積み重なったときI/Oコストの増大が発生し、そのパフォーマンス改善を狙って分割してしまう
【問題点】
- 分割する明確な理由がなく、正規化の理論からは生成されていない。
- 拡張性に乏しく、前年度のデータを総なめで検索できない。また、テーブルが次々と増えていき、その度にアプリケーションの改修が必要となってくる
- パーティション機能など他の代替手段がある。
【対策】
- パーティション機能を活用することで、パフォーマンス改善が期待できる。
例えば年度で分けたいなら、そこをパーティションで物理的に格納領域を分離することでSQLがアクセスするデータ量を1/nに減らすことができる。
(インデックスとの比較もあるが、一般的にパーティションはインデックスよりもカーディナリティが小さく値の変更があまり起きない列をキーとして利用する。)
垂直分割
【症状】
列を軸にテーブルを分割してしまうこと
例えば、社員テーブルを「社員ID・年齢」と「社員ID・名前・部署コード」といった形で分割してしまう。
【なぜ起こるか?】
I/Oがボトルネックになったときのパフォーマンス改善として、実装されてしまう。
【問題点】
- 正規化でこそなく、無損失分解(分解後も分解前の状態に戻せること)であるものの、分割することに論理的な意味を持たない。
- 「集約」で代替可能であること。
【対策】
- 「集約」を扱う。
- 保持する列を絞ったテーブルを作成する。
- オリジナルのテーブルは残して、頻繁に参照される列のみで別の「社員テーブル」を作成する。こういったテーブルをデータマートという。しかしながら、この方法を使う場合は オリジナルのテーブルと同期しなければならないためその頻度のチューニングが必要となる。精度を高くしようとすれば更新頻度が高くなり、更新の負荷が上がってしまう。逆に更新頻度を低くするとオリジナルのテーブルとデータマート不整合の期間がながくなり、 マートの値を使って問題ないかを慎重に検討する必要が出てくる。
- サマリーテーブル
- 集約関数によってレコードを集約した状態で保持する。例えば平均年齢を算出する必要がある場合、テーブル規模が大きくなると毎回実行する集約処理のコストが大きくなるため、実行時間が長くなる。このとき事前に集約を行ったテーブルを作っておくことで目的の平均年齢を単純なSELECT文で取得することができる。また、整合性が取れない期間があるというデメリットが発生することはこの対処方法でも同様。
- 保持する列を絞ったテーブルを作成する。
最後に
これまで紹介させていただいたアンチパターンは、自分自身も実際に現場で目にした例も多かったです。
そして、バックエンドエンジニアとして業務経験が浅かった頃は、1列に集約関数実行後の値をjson文字列で格納した変なサマリーテーブルを作ったことも有りました。。。
そのような実装をしてしまう前にアンチパターンを知っておくことで事故を防ぎ、今後の保守や運用の効率が上がって行くかと思います。
この記事が少しでも皆さんの設計のヒントになれば嬉しいです!