最近ではAI技術が急速に発展し、ChatGPTなどの人工知能や機械学習を使った開発が注目されています。
そこで今回は、機械学習に興味はあるけど詳しくわからないという人に向けて、機械学習の基礎知識や実際に開発する際の基本的な手順を説明します。
機械学習とは
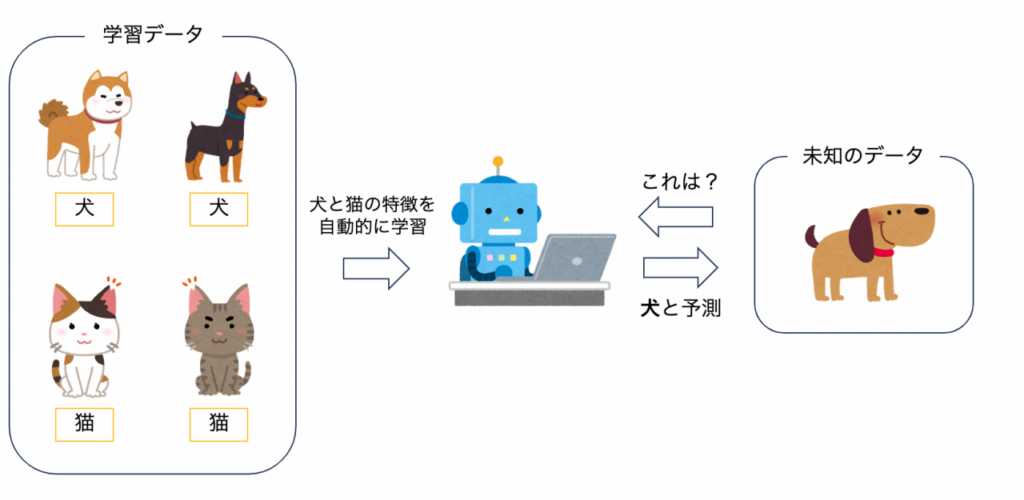
機械学習はコンピュータがデータから学習し、予測や意思決定を行う能力を持つ技術です。
データを解析し、パターンや関係性を自動的に学習して、未知のデータに対して予測や分類を行うことができます。
AIと機械学習の違い
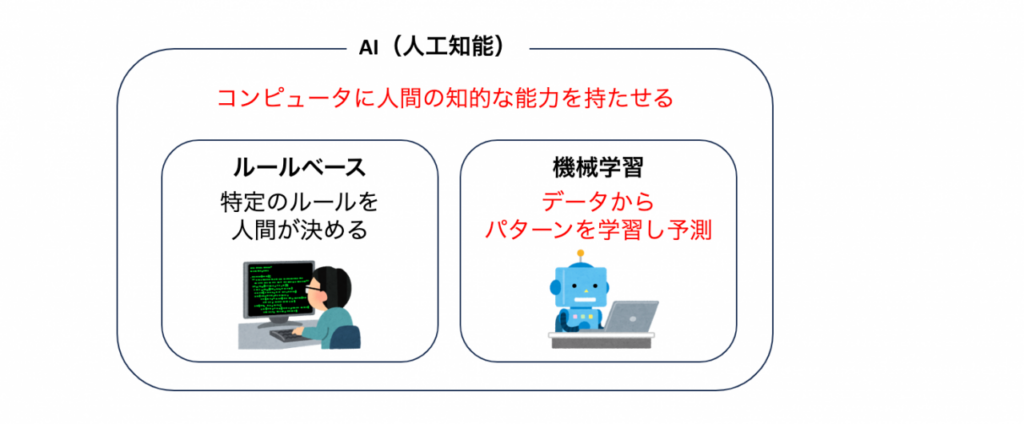
AI(人工知能)は、コンピュータに人間の知的な能力を持たせる技術を指し、機械学習はAIの一部でありデータからパターンを学習して予測や意思決定を行う手法です。
AIには機械学習以外の手法やルールベースのアプローチも含んでおり、人間の知的な能力を持たせるため幅広い技術を使用しています。
機械学習でできること
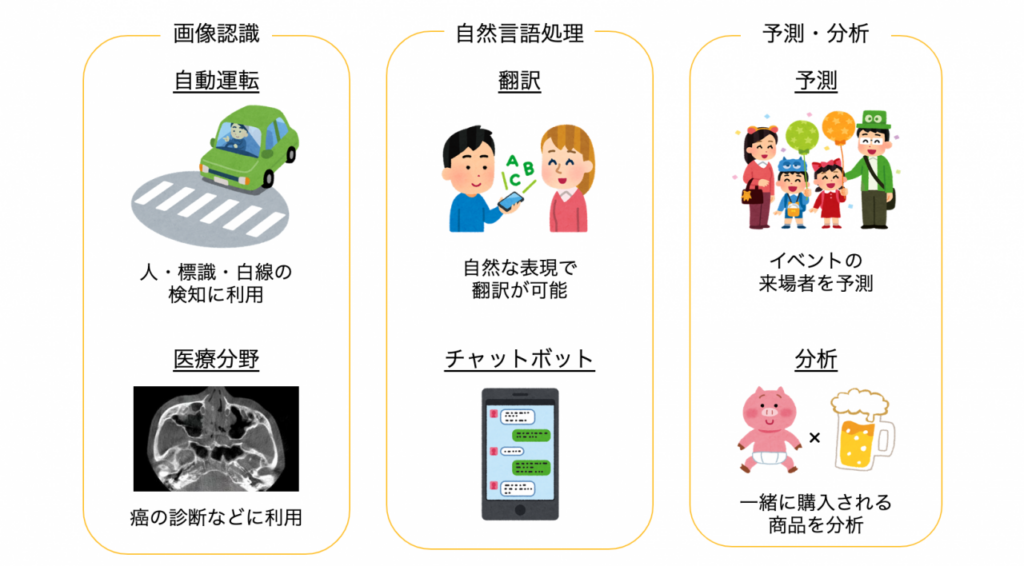
機械学習では画像認識や音声認識、自然言語処理、レコメンドシステム、不正検知、予測分析などの様々なタスクをこなすことが可能です。
機械学習の種類
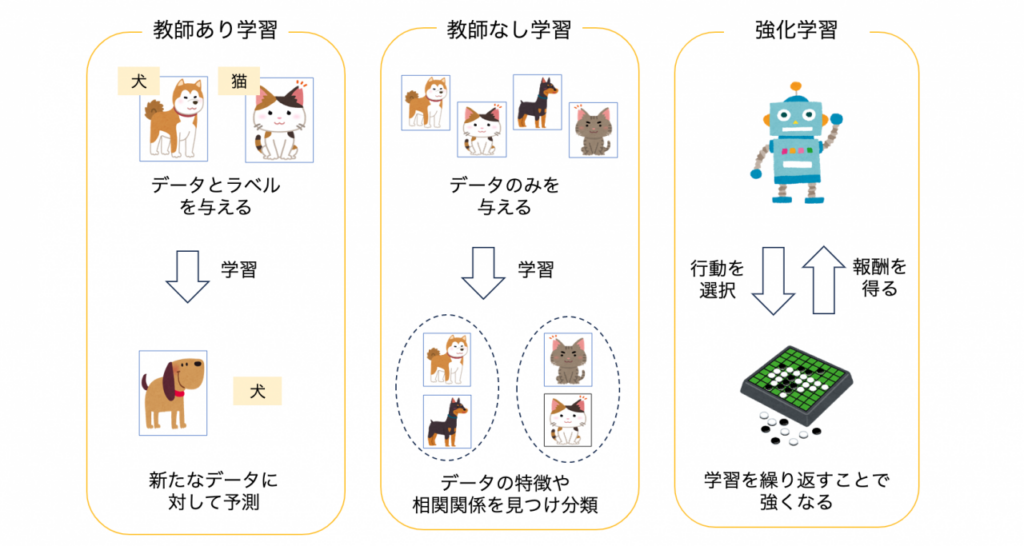
機械学習は一般的に「教師あり学習」「教師なし学習」「強化学習」と呼ばれる3つの分類に分けられます。
教師あり学習
データとそれに対応するラベル(正解値)を与えることで、モデルはパターンや関連性を学習し、新たなデータに対して予測や分類を行います。
教師なし学習
ラベルのないデータを用いてパターンや構造を見つける手法です。データ自体の特徴や相関関係を抽出し、クラスタリングや次元削減などのタスクを実行します。
強化学習
強化学習は、コンピューターがゲームや問題を解く方法を学ぶ方法です。コンピューターは、行動を選択し、それによって得られる報酬を最大化するために学習します。
例えば、オセロではどこに石を置くかを選択し、それによってとれた石の数を報酬とします。この報酬を元に繰り返し戦略を改善していくことで精度を強化することができます。
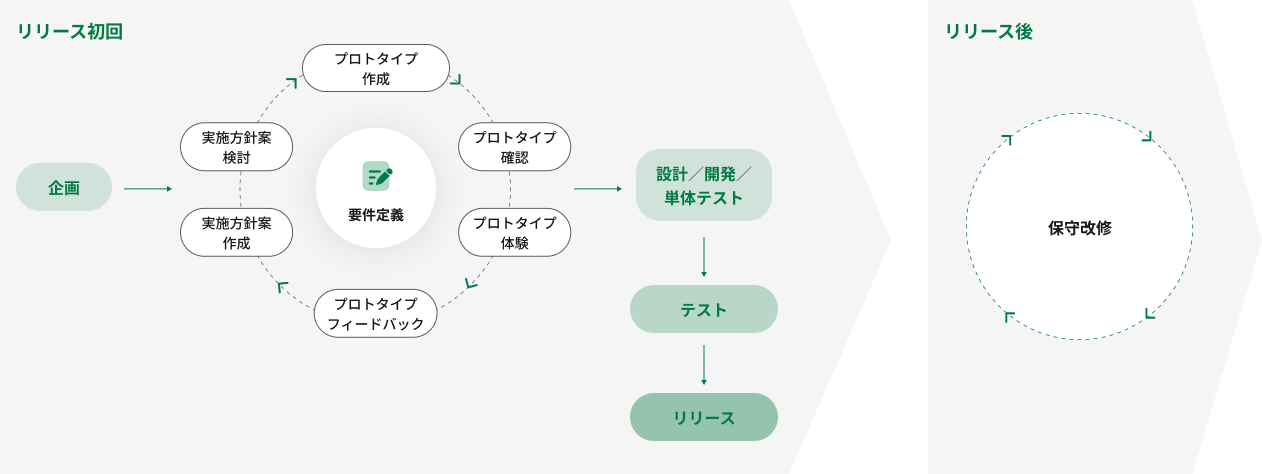
機械学習を使用した開発の手順
ここでは教師あり学習を例に、機械学習を使った開発を行う場合の手順を説明します。
データセットの準備
機械学習では、学習のためにデータが必要です。データセットは入力データとそれに対応する正解データ(ラベル)から構成されます。
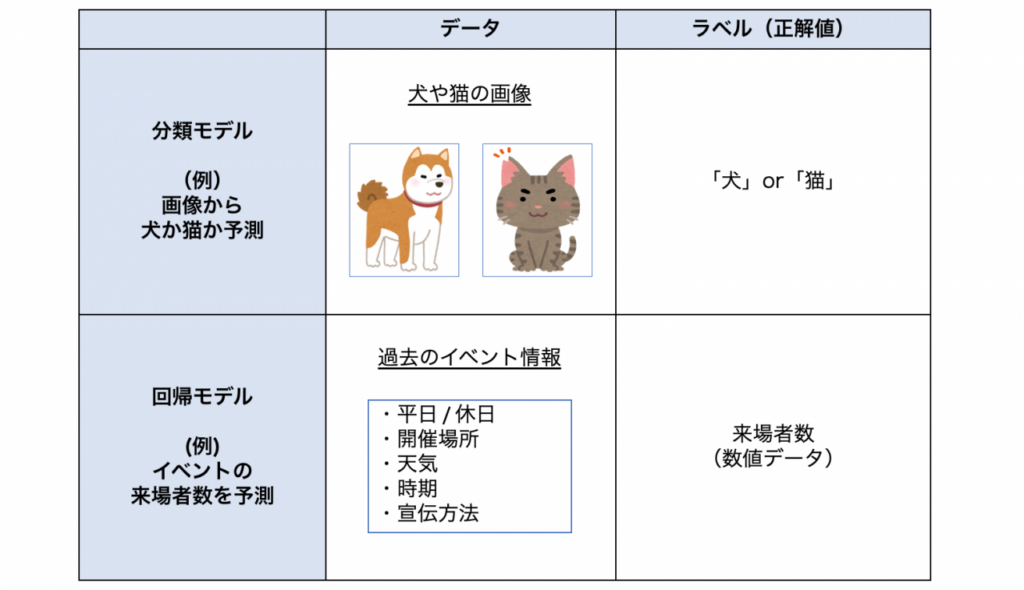
この準備の工程が、機械学習においては非常に重要で大変な作業となります。例えば、分類モデルではクラス(犬or猫)ごとに約1000~10000枚の画像を必要とします。膨大なデータを集めることは容易ではないため、枚数が足りない場合は画像の回転や拡大縮小、反転などを用いてデータを水増しして作成します。
モデルの選択と学習
回帰モデル、分類モデルともに複数の手法があるので適したモデルを選択し、準備したデータセットを使用してモデルに学習させます。
回帰モデルの主な例として線形回帰や決定木(XGBoost, LightGBM)など、分類モデルにはSVM(サポートベクタマシン)、ロジスティック回帰、k近傍法などがあります。
予測
学習が完了したモデルを使用して、新しいデータの予測を行います。予測結果は、分類問題の場合はクラスのラベル、回帰問題の場合は数値として表現されます。
モデルの評価
作成したモデルに対し、予測結果の正確さや性能を評価します。一般的な評価指標には、分類モデルでは正解率や適合率、回帰モデルではRMSEや決定係数と呼ばれる指標が使用されます。
おわりに
今回は、機械学習の基礎知識や開発手順を説明しました。この記事を通じて少しでも機械学習のイメージが掴めると嬉しいです。最後まで読んでいただきありがとうございました。