はじめに
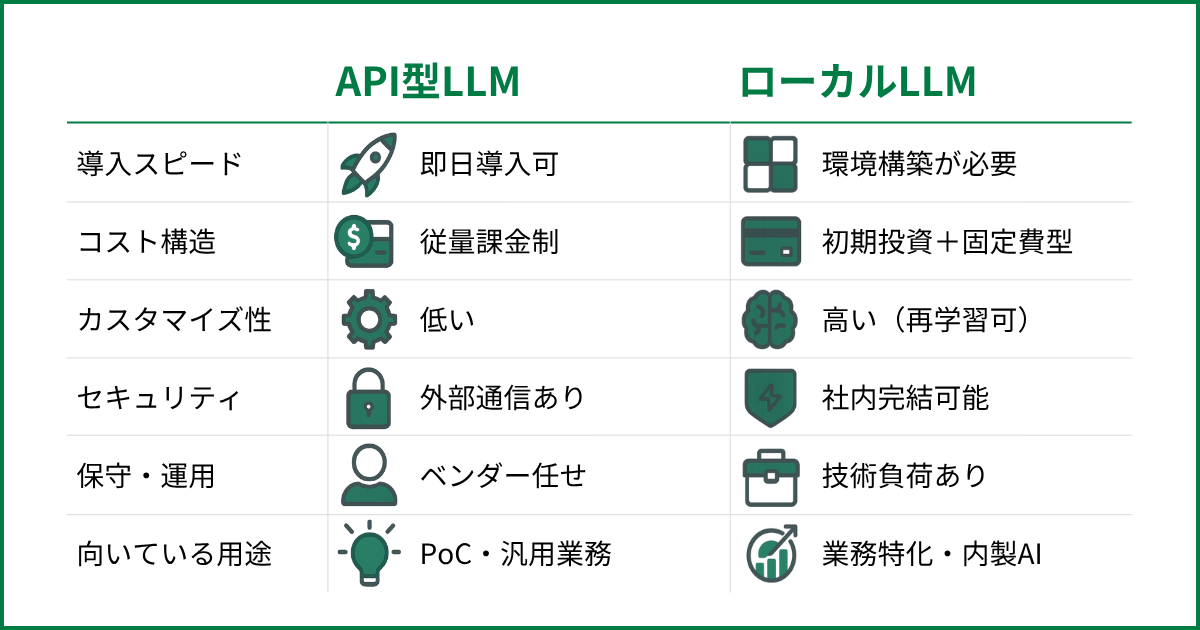
自社の制度やFAQなどを生成AIに理解させたいと考えたとき、まず悩むのが「AIにどうやって知識を渡せばいいのか」という点ではないでしょうか。
社内ドキュメントを検索させる仕組みが必要なのか、データベースを用意しなければならないのかと考えると、ハードルが高く感じてしまいます。
しかし、小規模な用途やPoCであれば、そこまで複雑な仕組みは不要です。
JSON形式で整理した事前知識をそのままAIに渡すだけでも、社内FAQ対応や簡単な業務サポートであれば、十分に実用的なAIを構築できます。
よく聞く「RAG」とは?
生成AIに事前情報を与える方法として、よく登場するのが「RAG(Retrieval Augmented Generation)」です。
RAGとは、AIが回答を生成する際に、外部のデータベースや文書を検索し、その結果を参照しながら回答する仕組みを指します。
大量の社内文書を横断的に検索したい場合や、情報量が非常に多いケースでは有効な方法ですが、検索基盤やデータ管理の設計が必要になるため、最初の取り組みとしては少しハードルが高く感じられることもあります。
この記事では、RAGのような仕組みを使わずに、まずはAIに必要な知識を直接教える方法を紹介します。
JSONを使った知識の組み込み
JSONとは?
JSON(JavaScript Object Notation)は、情報を「項目」と「値」の形で整理して表現できるデータ形式です。
人が読んでも分かりやすく、AIにとっても情報のまとまりを理解しやすいという特徴があります。
例:福利厚生情報をJSONで表現
{
"福利厚生": {
"住宅手当": "正社員に対し家賃の20%を補助(上限3万円)",
"通勤費": "公共交通機関の定期代を全額支給",
"健康診断": "年1回、全社員対象に実施"
},
"問い合わせ先": {
"総務部": "soumu@example.com"
}
}
プロンプトにJSONを使うメリット
JSONを使うことで、プロンプトの安定性や再現性が大きく向上します。主なメリットは次の3つです。
- 情報を構造的に整理できる
制度名・条件・詳細などの関係性を明確にでき、AIが文脈を誤読しにくくなります。 - 簡単に更新できる
RAGのようにデータベースを再構築する必要はありません。JSONを書き換えて再読み込みするだけで、内容を反映できます。 - 回答精度が安定する
構造化された情報を渡すことで、AIの推論が安定し、いわゆる「幻覚(hallucination)」の発生を抑えやすくなります。
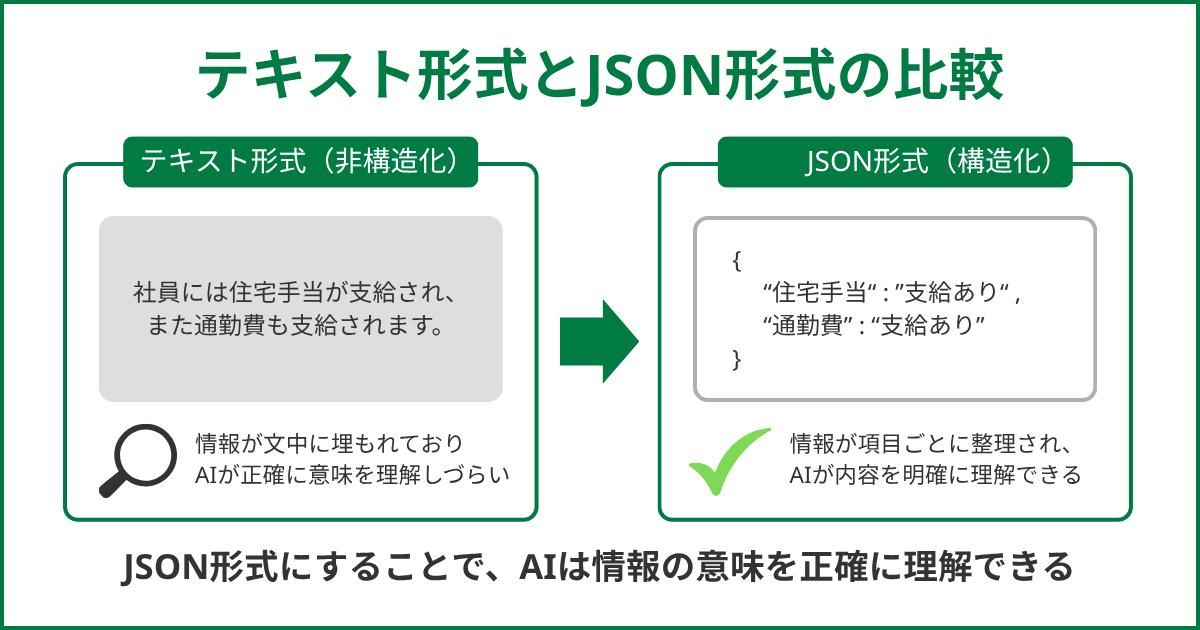
テキストとJSONの比較
テキスト形式では、情報が文章の中に埋もれてしまい、AIが正確に意味を把握しづらくなります。
一方で、JSON形式は項目ごとに情報を整理できるため、内容を明確に理解させることが可能です。
実践例
ここでは、Pythonを使って社内FAQ AIを構築する手順を紹介します。
OpenAIのChatGPT APIを利用し、JSON形式でまとめた社内知識をAIプロンプトに組み込む方法を実装します。
1. JSONファイルを作成
まず、FAQや社内制度などの知識を構造化してknowledge.jsonとして保存します。
{
"休暇制度": {
"有給休暇": "勤続6か月後に10日付与",
"リフレッシュ休暇": "勤続3年ごとに3日間の特別休暇を付与"
},
"福利厚生": {
"書籍購入補助": "業務に関連する書籍を年間2万円まで会社負担で購入可能",
"食事補助": "社員食堂を1食300円で利用可能"
}
}
2. PythonでJSONを読み込みAIに渡す
次に、作成したJSONをPythonで読み込み、プロンプトに組み込みます。
import json
from openai import OpenAI
client = OpenAI(api_key="YOUR_API_KEY")
with open("knowledge.json", "r", encoding="utf-8") as f:
knowledge = json.load(f)
prompt = f"""
あなたは社内FAQアシスタントです。
以下のJSONを参照して、質問に最も関連する情報を回答してください。
回答は必ずJSON内の情報を優先してください。
【事前知識JSON】
{json.dumps(knowledge, ensure_ascii=False, indent=2)}
"""
question = "リフレッシュ休暇は誰が対象ですか?"
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": prompt},
{"role": "user", "content": question}
]
)
print(response.choices[0].message.content)
出力例
A: 勤続3年以上の社員が対象です。3日間のリフレッシュ休暇が付与されます。
応用編:大規模な知識データの扱い方
知識量が増えてくると、AIの入力上限(トークン制限)や処理コストが課題になります。ここでは、データ量が増えた場合に有効な工夫を紹介します。
1. 要約の格納
規程やマニュアルなどが長文の場合は、要点をまとめた概要をJSONに含めておくと効果的です。
{
"勤務制度_概要": "フレックス制・リモートワーク制度を導入。詳細は別途規程参照。"
}詳細は別ドキュメントで管理し、AIには概要だけを渡すことで、トークン使用量を抑えつつ必要な情報を伝えられます。
2. カテゴリ別分割とスコープの制御
AIに大量の知識データを一度に渡すと、処理が重くなり、効率も低下しがちです。
そこで有効なのが、情報をカテゴリごとに分割し、質問内容に応じて必要な部分だけを読み込む「スコープ制御」という考え方です。
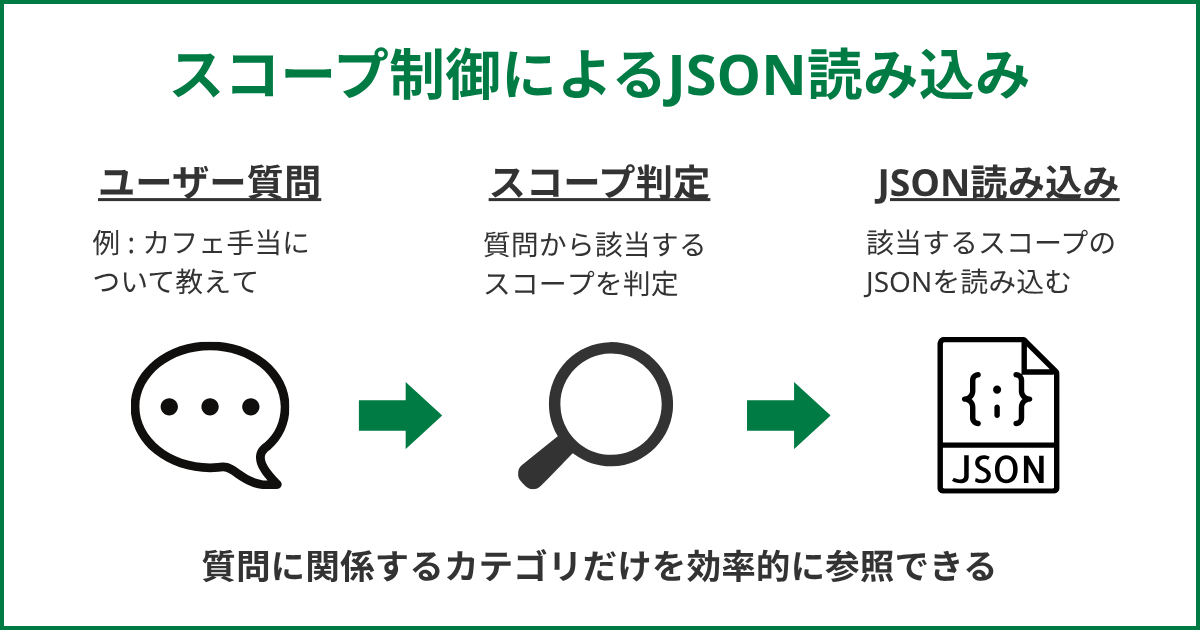
スコープ制御の流れ
- ディレクトリ構造を整理する
まず、JSONファイルをカテゴリ単位で管理できるように、次のようなディレクトリ構成にします。
📁 knowledge/
├── 福利厚生.json
├── 勤務制度.json
└── 人事関連.json- 質問内容からスコープを判定する
ユーザーから質問が来たら、その内容をもとに、どのカテゴリに該当するかを判定します。
たとえば「カフェ手当について教えて?」という質問であれば、「福利厚生」に関する内容だと判断します。 - 対象となるJSONだけを読み込む
判定結果に応じて、「福利厚生.json」だけを読み込み、AIに渡します。
このように必要な知識だけを扱うことで、処理負荷を抑えつつ、安定した回答を得やすくなります。
まとめ
RAGを使わなくても、JSON形式を活用すれば、生成AIに必要な知識を直接与えることができます。
情報を整理して渡すことで、回答の安定性が高まり、誤った回答も減らしやすくなります。
特に、小規模なプロジェクトやPoCのように、まずは小さく試したいケースでは、この方法が有効です。
JSONでシンプルに仕組みを作り、手応えを確認したうえで、必要に応じてRAGを検討する。そうした段階的な進め方が、無理なく生成AIを業務に取り入れる近道になります。
お読みいただきありがとうございました。