はじめに
2024年問題でドライバー不足と配送効率の改善が迫られる運送会社に対し、GPS・デジタコ・ドラレコから得た生データを収集基盤へ取り込み、移動・停止・荷待ち・荷役といった業務イベントへ変換するデータ整備から着手することで、ETA予測や配車最適化、異常検知といった分析・AI活用の土台を整えられます。
課題・背景
物流業界では2024年問題をきっかけに、ドライバーの労働時間規制や配送効率の改善が同時に求められるようになりました。現場ではすでにGPS端末、デジタコ、ドラレコなどから運行データを取得している会社も多いはずです。データそのものは手元にあるのに、分析や意思決定に使えない——ここで立ち止まるケースを、私たちはよく見ます。
- 課題①:GPSの時刻・緯度・経度・速度が羅列されたまま残り、業務上の意味を持つ形に整備されていない
- 課題②:AIや高度な分析の導入を先に検討する一方で、データの収集基盤や変換ロジックが未整備のまま進んでいる
- 課題③:ベテランの経験則を文章化してAIに渡せば解決する、という発想に寄りすぎて、過去の運行データという手堅い資産を活かしきれていない
物流DXで最初にやるべきことは、いきなり生成AIを入れることではありません。データを集め、蓄積し、キレイに整える——この順番を踏まないと、どんなに高度なモデルを導入しても現場の判断材料にはなりません。
データ整備・実践ステップ
物流DXのデータ整備は、大きく3段階に分けて進めます。車両からデータを取る、クラウドへ取り込む、業務イベントへ変換する——この流れを押さえておけば、あとからETA予測や配車最適化を足すときに迷いが少なくなります。
ステップ①:車両からデータを収集する
最初の関門は、何をどの粒度で取るかを決めることです。取得手段によってコストと情報量が大きく変わるので、全車両をいきなり高機能機器に揃える必要はありません。PoCで試してから拡張する進め方の方が、現場の負担も小さく済みます。
3つのパターンを比較すると、次のようになります。
| パターン | 導入コスト | メリット | デメリット |
|---|---|---|---|
| 車載IoT機器 | 高 | 取得項目が豊富で信頼性が高い | 端末・設置・通信費が高く、後付けは手間 |
| シガーソケット型GPS | 中 | 後付け容易、数台から試せる | 取得項目が少ない、抜け忘れで欠損しやすい |
| スマホアプリ | 低 | 端末不要で最安、導入が容易 | 端末依存、取得漏れ・運用負荷あり |
コストの観点では、スマホアプリが最も安く、車載IoT機器が最も高くなります。ただし安いほど運用負荷がドライバー側に寄る、というトレードオフがあります。データ整備の仕組みを作る段階なら、シガーソケット型GPSかスマホアプリから始めて、仕組みが固まってから車載IoTへ広げる進め方が現実的です。
車載IoT機器・シガーソケット型GPSのイメージ図
比較表だけでは形状の違いが伝わりにくいため、イメージ図を掲載します。特定メーカーの製品ではなく、物流の現場でよく見る端末の形状イメージです。実際の導入時は、取得項目やコストに応じてメーカー・型番を選定してください。
車載IoT機器
ダッシュボード裏や車内に固定設置する、手掌サイズのボックス型端末です。GPSアンテナ・通信モジュール・車両情報の取得回路が一体化しており、シガーソケットへの抜き差しが不要なのが特徴です。エンジン状態や燃費など、取得項目が多い端末に多い形状です。
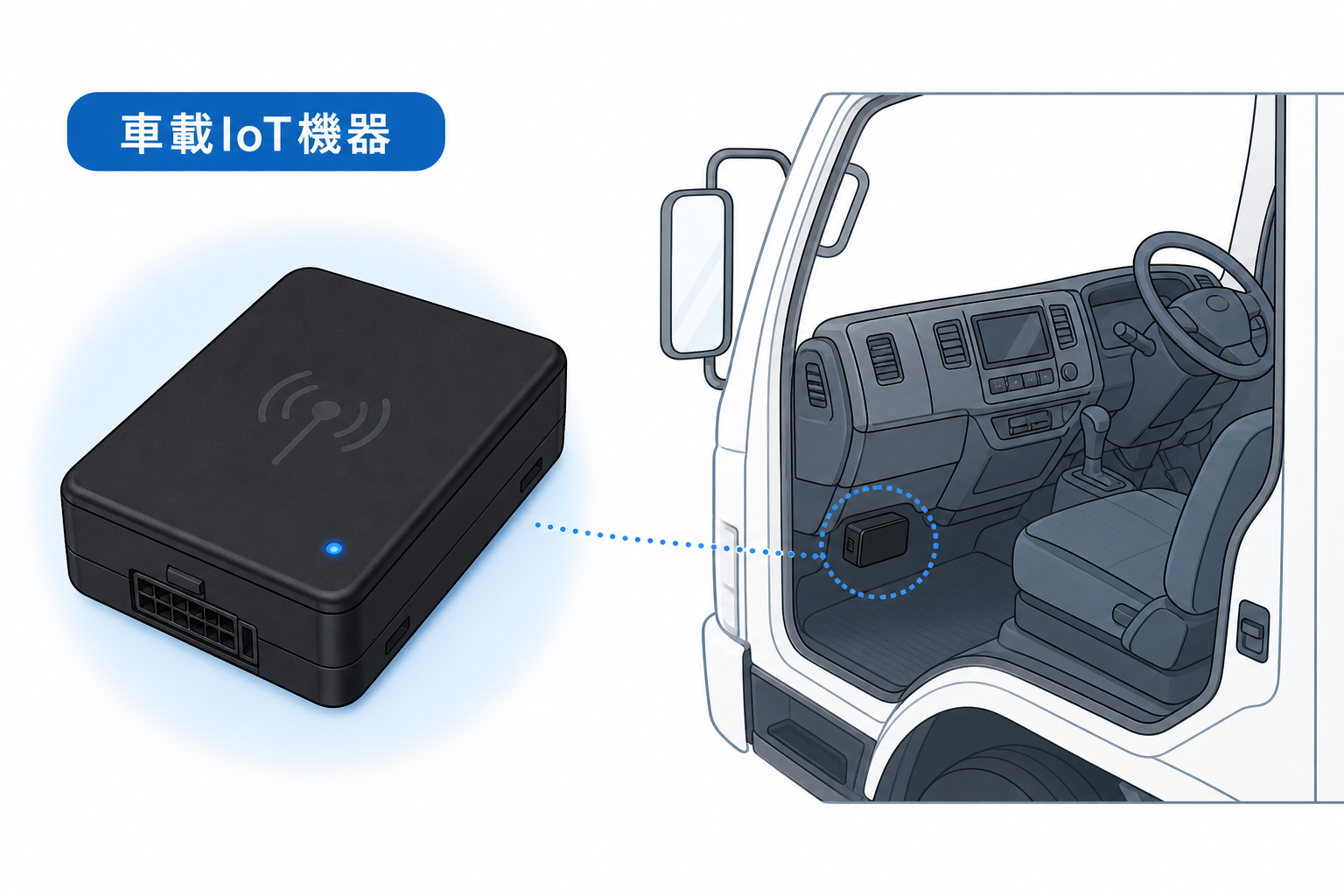
シガーソケット型GPS
シガーソケット(またはOBD2ポート)に挿すだけで使える、小型のドングル型端末です。本体が小さく、数分で後付けできるのが特徴です。取得項目はGPSと速度に絞られますが、データ整備のPoCを素早く始めたい場合によく選ばれます。

ステップ②:データを収集基盤へ取り込む
車両から送られたデータは、そのまま分析に回すのではなく、まずクラウド上の収集基盤へ流し込みます。車両台数によって構成は変わります。小規模ならシンプルに、台数が増えたらスパイクを吸収する仕組みを足す——この段階的な設計が現実的です。
収集基盤にも3つのパターンがあり、コストと運用の手間が段階的に変わります。
| パターン | インフラコスト | メリット | デメリット |
|---|---|---|---|
| Lambdaのみ | 低 | シンプルで安価 | スパイクでLambdaやDBが詰まる |
| Kinesis利用 | 中 | スパイク吸収、運用負荷が軽い | 設計・調整が必要 |
| Kafka利用 | 高 | 大規模・多配信向き | 運用・コストが高い |
KinesisとKafkaはどちらもストリーミング層(スパイク吸収・バッファ)の役割を担い、下流の Lambda → Timestream → S3 は同じ構成です。違いは下流ではなく、規模と運用の複雑さにあります。コストの観点では、Lambdaのみが最も安く、Kafkaが最も高く、Kinesisはその中間です。数台のPoC段階でKafkaまで用意する必要はなく、負荷の偏りが見えてから段階的に足す方が、コストと運用負荷のバランスが取れます。
各パターンの構成図は次のとおりです。
パターン1:Lambdaのみ(数台〜10台・低コスト)
GPS端末 → API Gateway → Lambda → DB
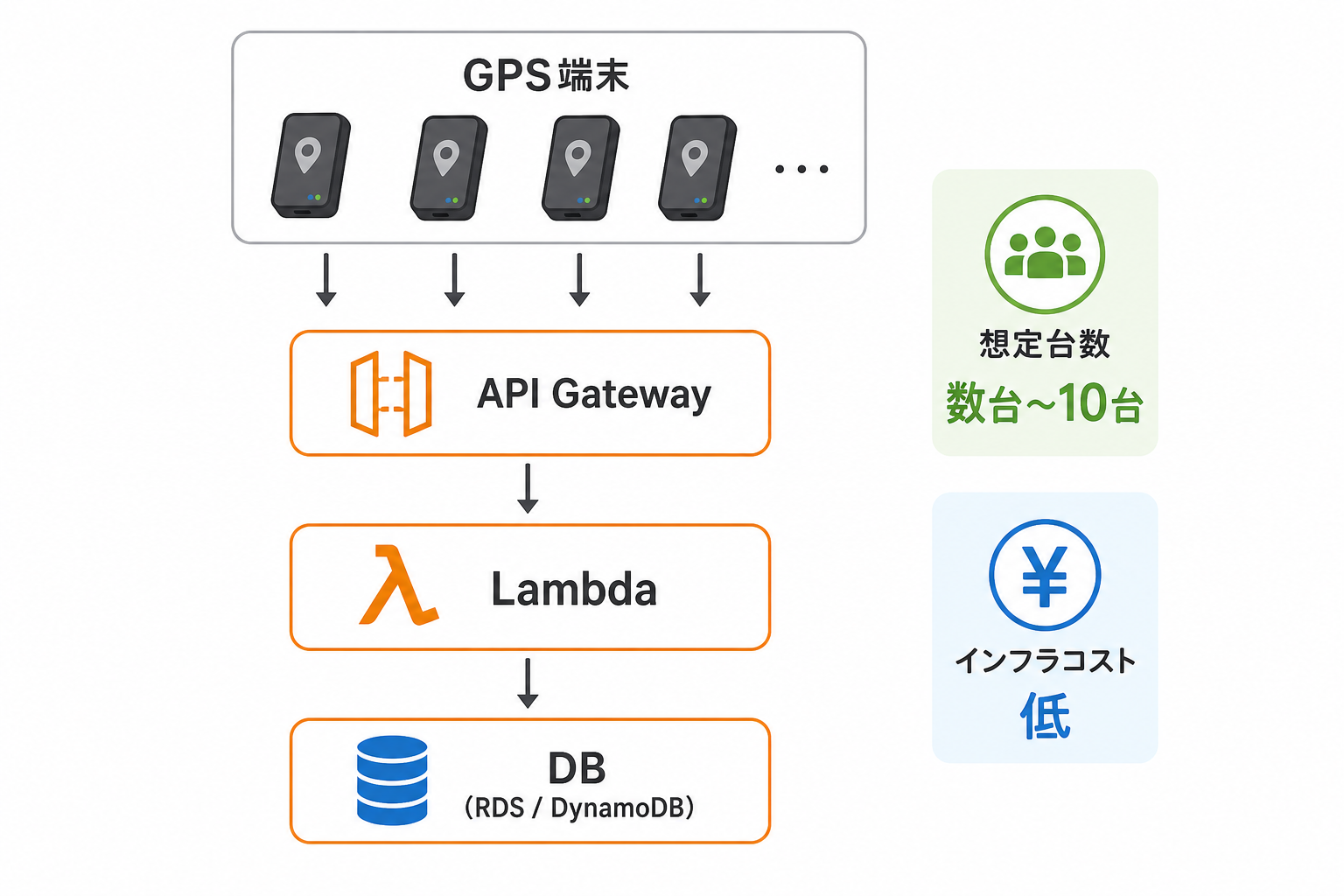
パターン2:Kinesis利用(10〜100台・中コスト)
GPS端末 → API Gateway → Kinesis Data Streams → Lambda → Timestream → S3
Kinesisが朝の一斉出発のスパイクを吸収し、Lambdaがイベント変換を行い、Timestreamに時系列データを蓄積、S3に長期保管用データを置く流れです。中堅運送会社がサーバーレス中心で本番運用する場合の標準構成になります。

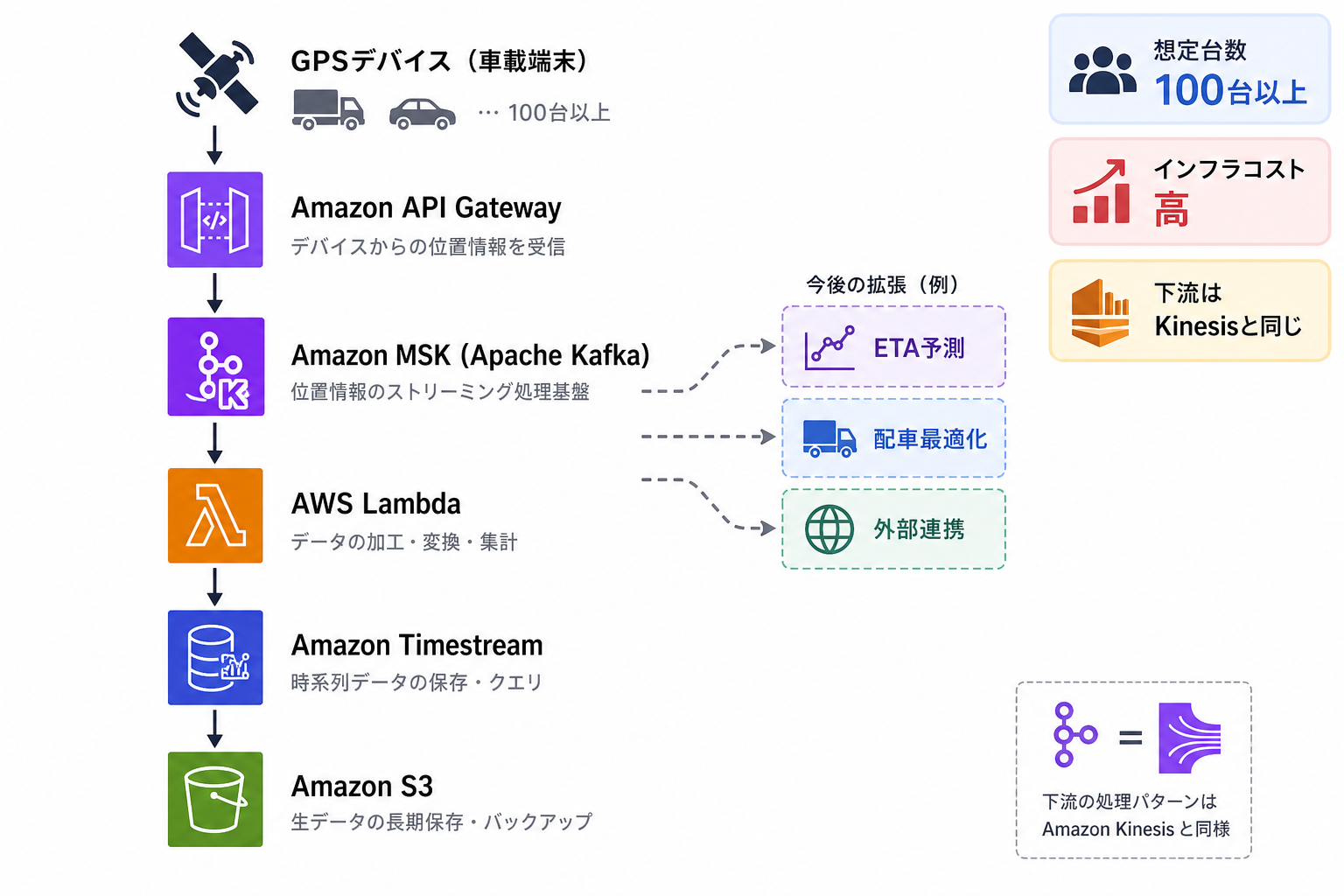
パターン3:Kafka利用(100台以上・高コスト)
GPS端末 → API Gateway → Kafka → Lambda → Timestream → S3
下流はKinesis利用と同じです。変わるのはKinesis Data Streamsの代わりにKafkaを置く点だけです。Kafkaは大容量・高スループットに耐え、複数の下流システムへデータを配信しやすいため、台数が100台を超えたり、ETA予測・配車最適化・外部連携先など複数のコンシューマーに同じデータを届ける必要が出てきた段階で選ばれます。
予算を抑えたい会社へのおすすめ
予算に余裕がない会社に、私たちがよく勧めるのはシガーソケット型GPS + Kinesis利用の組み合わせです。
| 項目 | おすすめ | 理由 |
|---|---|---|
| データ収集 | シガーソケット型GPS | 車載IoTより安価で、スマホアプリよりデータの信頼性が高い。 |
| 収集基盤 | Kinesis Data Streams | Lambdaのみより月額費用は上がるが、朝の一斉出発のスパイクを吸収できる。 |
車載IoTやKafkaは性能・拡張性に優れますが、初期投資と運用コストが重くなります。予算が限られているなら、まずこの組み合わせでデータ整備の仕組みを動かし、効果が見えてから車載IoTの導入やKafkaへの切り替えを検討する進め方が現実的です。
もっと費用を抑えたい場合は、スマホアプリ + Lambdaのみが最安です。ただしドライバー側の運用負荷が増え、データ欠損も起きやすくなります。数台だけ試す短期PoCなら選択肢になりますが、本番運用を見据えるなら、わずかな追加コストでシガーソケット型GPSとKinesisを選んだ方が、あとから作り直す手間は少なく済みます。
ステップ③:データをキレイに整える
この記事の主役は、生のGPSデータを業務イベントへ変換する工程です。時刻・緯度・経度・速度の羅列は、そのままでは「何が起きていたか」を読み取れません。配送の現場で使う言葉——移動、停止、荷待ち、荷役——に変換して初めて、分析の材料になります。
変換の考え方はシンプルです。速度や位置の変化にルールを当てはめ、一定条件が続いたらイベントとして確定させます。4つのイベントの判定例は次のとおりです。
| イベント | 判定例 |
|---|---|
| 移動 | 速度が一定以上で走行が続いている |
| 停止 | 速度0km/hが数分未満で再開する(信号待ちや一時停車) |
| 荷待ち | 倉庫や待機場のジオフェンス内で、速度0km/hが15分継続 |
| 荷役 | 配送先のジオフェンス内で、速度0km/hが20分継続 |
ジオフェンスとは
ジオフェンス(Geofence)とは、地図上のある地点を中心に、円や四角で区切った仮想のエリアのことです。geo(地理)と fence(柵)を合わせた言葉で、車両のGPSがその範囲に入ったか・出たかをシステムが自動判定します。
配送先の住所や倉庫の位置をもとに、数十メートル〜数百メートルの範囲をあらかじめ登録しておきます。たとえば「○○商事 東京支店」の配送先ジオフェンスを設定しておけば、トラックがそのエリアに入ったタイミングで「到着した」と判断できます。エリア内で長時間停車していれば、道路上の渋滞ではなく荷役の可能性が高い——という推定にもつながります。
| ジオフェンスの種類 | 登録する場所 | イベント判定での使い方 |
|---|---|---|
| 倉庫・待機場 | 拠点の住所を中心にしたエリア | エリア内の長時間停車 → 荷待ち |
| 配送先 | 各配送先の住所を中心にしたエリア | エリア内の長時間停車 → 荷役 |
エリアの大きさは現場の運用に合わせて調整します。小さすぎると駐車位置がずれただけでエリア外になり、荷役と判定されません。大きすぎると近くの道路上でもエリア内とみなされ、誤判定が増えます。まずは代表的な配送先から登録し、判定結果を見ながら範囲を詰めていく進め方が現実的です。
「信号や渋滞で止まっているのに、荷待ちと同じに判定されないか」——ここが設計の肝です。信号待ちは通常数分以内で再開するため、「停止」として扱われ、荷待ちにはなりません。一方、渋滞で15分以上止まった場合は、速度と時間だけでは荷待ちと区別できず、誤判定のリスクがあります。
そのため荷待ちと荷役では、速度・時間に加えてジオフェンス(場所の条件)を組み合わせます。倉庫や待機場のエリア内で長時間止まれば荷待ち、配送先のエリア内で長時間止まれば荷役——と場所で意味を分けることで、道路上の渋滞とは切り分けやすくなります。閾値(何分で荷待ちとみなすか)は、現場の運用とすり合わせながら調整します。
ルールだけではイメージしにくいので、生データがイベントに変わる具体例を3つ挙げます。
例1:信号待ち →「停止」
| 時刻 | 速度 | 位置 |
|---|---|---|
| 10:00 | 40km/h | 国道沿い(ジオフェンス外) |
| 10:01 | 0km/h | 国道沿い(ジオフェンス外) |
| 10:02 | 0km/h | 国道沿い(ジオフェンス外) |
| 10:03 | 35km/h | 国道沿い(ジオフェンス外) |
→ 10:01〜10:03の2分間を「停止」と記録。再開まで数分未満なので、荷待ちにはなりません。
例2:倉庫で待機 →「荷待ち」
| 時刻 | 速度 | 位置 |
|---|---|---|
| 09:00 | 0km/h | 倉庫ジオフェンス内 |
| 09:05 | 0km/h | 倉庫ジオフェンス内 |
| 09:10 | 0km/h | 倉庫ジオフェンス内 |
| 09:15 | 0km/h | 倉庫ジオフェンス内 |
→ 09:00から15分間、倉庫内で速度0が続いたため、09:15時点で「荷待ち」と確定。
例3:配送先で作業 →「荷役」
| 時刻 | 速度 | 位置 |
|---|---|---|
| 14:00 | 10km/h | 配送先ジオフェンスに進入 |
| 14:05 | 0km/h | 配送先ジオフェンス内 |
| 14:15 | 0km/h | 配送先ジオフェンス内 |
| 14:25 | 0km/h | 配送先ジオフェンス内 |
→ 14:05から20分間、配送先内で速度0が続いたため、14:25時点で「荷役」と確定。
変換後のイベントデータは、次のような形で蓄積されます。
| 開始時刻 | 終了時刻 | イベント | 場所 |
|---|---|---|---|
| 10:01 | 10:03 | 停止 | 国道沿い |
| 09:00 | 09:15 | 荷待ち | 倉庫 |
| 14:05 | 14:25 | 荷役 | 配送先A |
生データの羅列が、このように業務の意味を持つ記録へ変わります。分析やダッシュボードは、このイベントデータを集計するだけで「荷待ちは何分」「荷役は何件」といった指標が取れるようになります。
ただし、GPSの生データはそのまま信用できません。トンネルや高架下で位置が飛ぶ、停車中なのに速度がゼロにならない——こうしたノイズを放置すると、イベント判定がずれます。GPS補正とカルマンフィルタで軌跡を滑らかにし、ジオフェンス判定で配送先や拠点との位置関係を確定させる——この前処理がデータ整備の肝になります。
実装はPythonとAWS Lambdaの組み合わせが扱いやすいです。KinesisやKafkaから流れてきたデータをLambdaで受け取り、補正・判定・イベント生成を行い、TimestreamやS3へ書き出す形がよく取られます。
そして。データ整備の先にある活用。
データ整備が進むと、次の活用につながる道が見えてきます。以下は、データ整備が進んだあとに検討しうる活用のイメージです。実際の画面構成や機能は、運用体制やデータの蓄積状況に応じて設計します。いずれも整備されたイベントデータを前提に、過去の運行データを分析して実現する領域です。詳細なモデル構築やアルゴリズム選定は、データが数週間〜数ヶ月分たまってからで十分です。
ETA予測(到着予測)
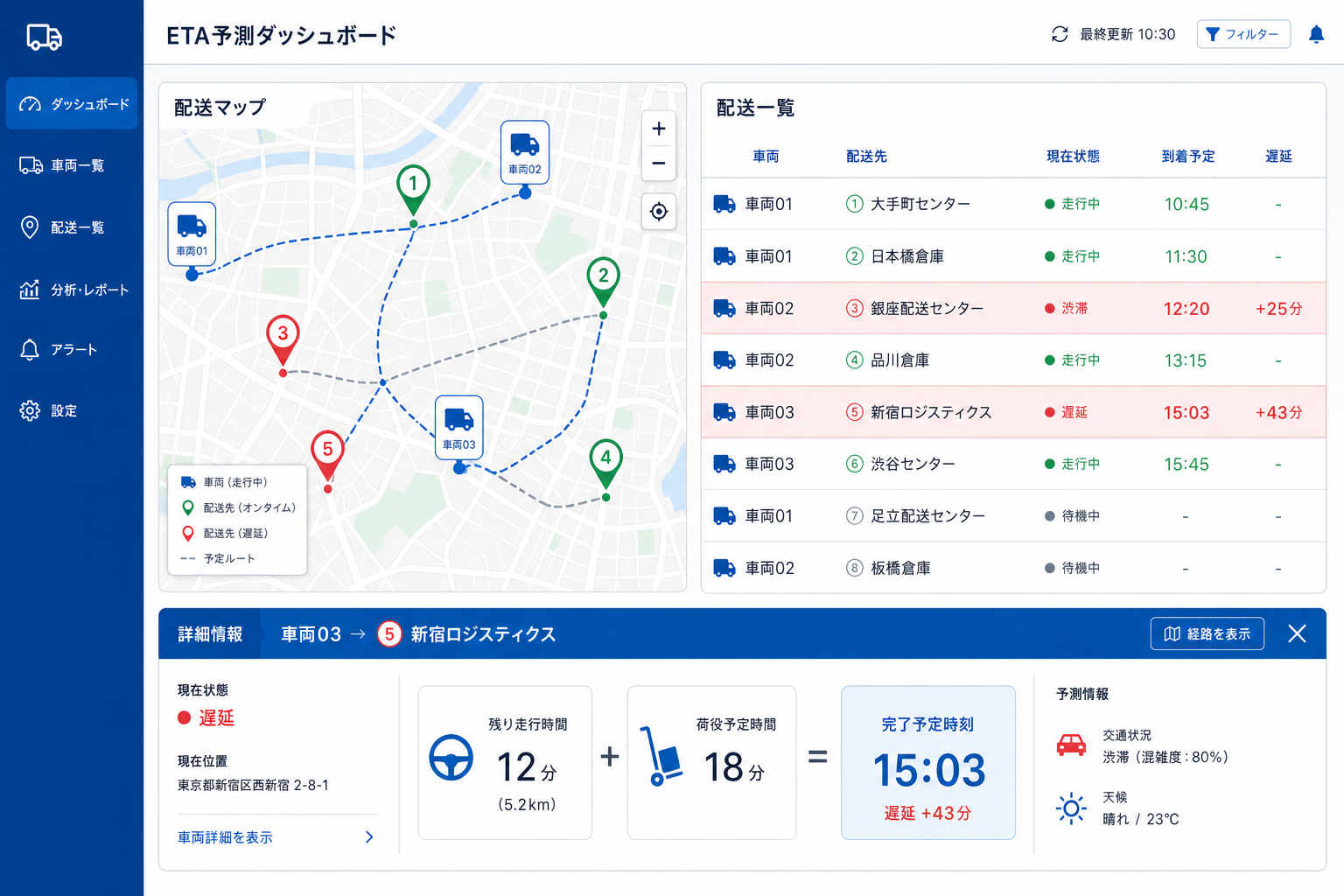
「何時ごろ着くか」がわかれば、荷受け側の待ち時間を減らせる可能性があります。過去の移動・停止・荷役のパターンから、ルートや時間帯ごとの所要時間を学習し、現在の位置と残りの行程から到着時刻を見積もる、という活用が考えられます。生のGPS速度だけでは「あと何分」とは読み取れませんが、「この配送先での荷役は平均18分」といったイベント単位の知見が使えるようになります。
配車室向けのETA予測では、地図と配送一覧を並べたダッシュボードが想定されます。表示イメージとしては、地図に車両の現在位置と配送先のピンを置き、一覧に各便の到着予定時刻と現在の状態を並べる構成が考えられます。
※ 以下は画面構成を説明するための想定例です。
| 車両 | 配送先 | 現在状態 | 到着予定 | 予定との差 |
|---|---|---|---|---|
| 品川1号 | ○○商事 | 移動中 | 14:45 | △5分遅れ |
| 品川2号 | △△倉庫 | 荷役中 | 15:10 | 予定通り |
| 横浜3号 | □□工場 | 荷待ち | 16:00 | △20分遅れ |
一覧の1行を選ぶと、到着予定の内訳を詳細パネルで確認する使い方が考えられます。残りの走行距離と走行所要時間に加え、過去データから算出した荷役予定時間を足すことで、荷役完了までの時刻を見積もるイメージです。「移動中」「荷役中」といった現在状態には、ステップ③で変換したイベントデータが反映される想定です。
ETA予測ダッシュボードのイメージ図
配車最適化・配送計画の最適化
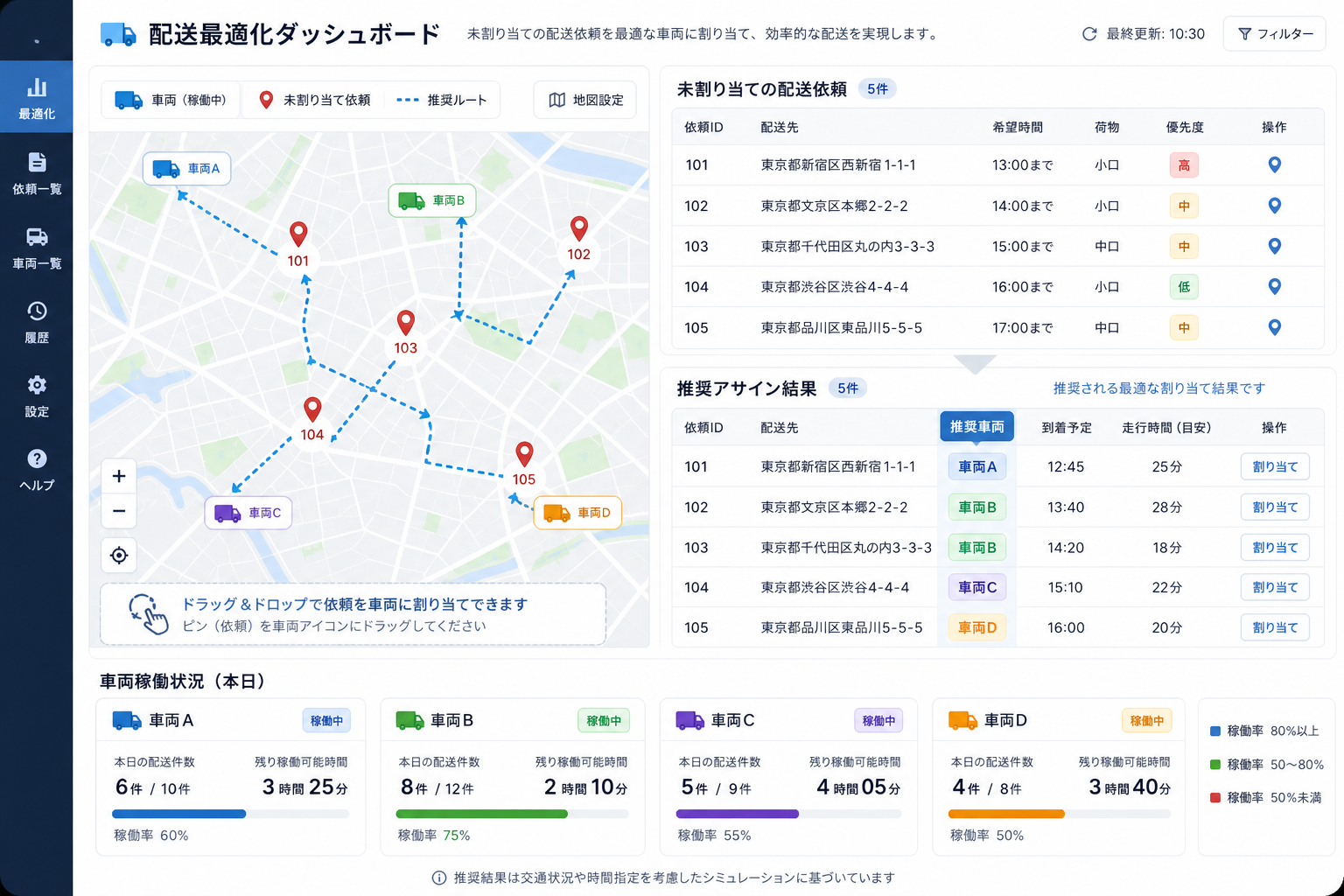
ドライバー不足のなかで1台あたりの配送件数を増やすには、走行中の車両がどこにいて、あと何件回れるかが見えている必要があります。荷役が終わった車両に近い配送先を割り当てる、荷待ちが長い便を別ルートに振り替える——こうした判断を、車両ごとの稼働状況データに基づいて自動化を検討できるようになります。配車室の経験則をそのままシステム化するのではなく、実際の稼働データから割り当てを導くアプローチが考えられます。
配車最適化では、未割り当ての配送依頼と車両の稼働状況を並べて表示する配車ボードを中心とした画面が想定されます。地図上に各車両の現在位置と割り当て候補の配送先を示し、推奨する組み合わせを一覧表示するイメージです。
※ 以下は画面構成を説明するための想定例です。
| 配送依頼 | 配送先エリア | 推奨車両 | 追加所要時間 | 推奨理由 |
|---|---|---|---|---|
| 依頼#1042 | 品川 | 品川1号 | +12分 | 荷役完了後、2km圏内 |
| 依頼#1043 | 横浜 | 横浜3号 | +25分 | 現在移動中、ルート順序が合う |
| 依頼#1044 | 川崎 | (未割当) | — | 稼働中の車両が不足 |
配車担当者が推奨案を確認して確定するか、手動で組み替える運用が考えられます。1台あたりの残り稼働時間や本日の配送件数も同じ画面で把握できるようにすると、2024年問題での労働時間管理とも両立しやすくなる領域です。
配車最適化ボードのイメージ図
異常検知
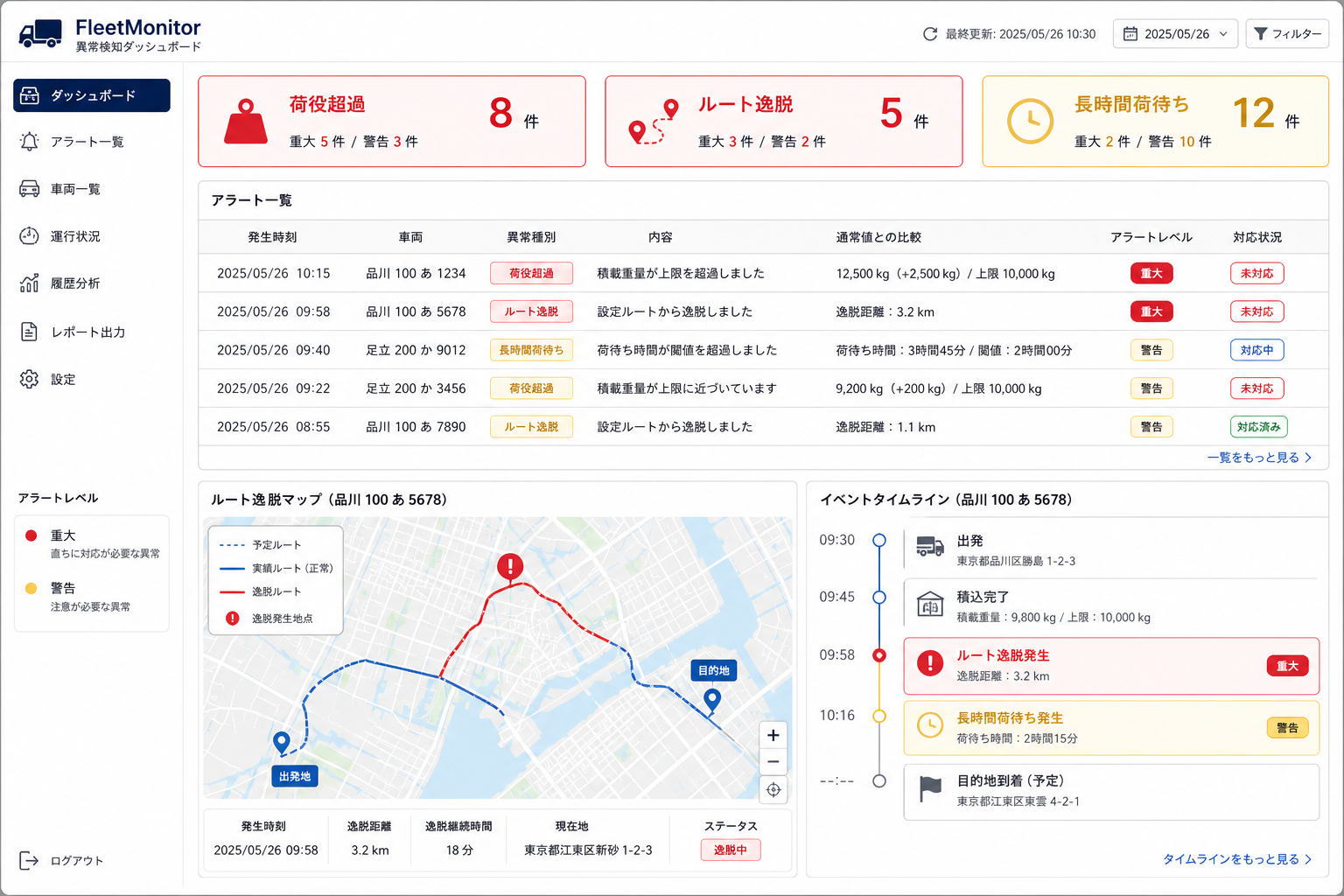
通常と違う動きを早期に拾う用途として検討されます。想定ルートから大きく外れたルート逸脱、通常よりはるかに長い荷待ちや荷役、営業時間外の長時間停車などが該当します。イベントデータがあれば、「この配送先ではいつも15分で終わるのに、今日は40分かかっている」といった比較が可能になります。ルールベースの閾値判定から始め、データがたまれば統計的な異常検知へ広げる進め方が考えられます。
異常検知では、アラート一覧を中心とした画面が想定されます。発生時刻の新しい順に並べ、異常の種類と対象車両をひと目で把握できる構成が考えられます。
※ 以下は画面構成を説明するための想定例です。
| 発生時刻 | 車両 | 異常種別 | 内容 | 通常値との比較 |
|---|---|---|---|---|
| 14:32 | 横浜3号 | 荷役超過 | △△倉庫で停車中 | 通常15分 → 現在40分 |
| 14:18 | 品川2号 | ルート逸脱 | 予定ルートから3km離脱 | — |
| 13:55 | 品川1号 | 長時間荷待ち | 倉庫で待機中 | 通常10分以内 → 現在28分 |
アラートを選択すると、地図上に該当車両の位置と経路、イベントの時系列を表示する使い方が考えられます。配車室が電話で状況確認に出る前に、データで異常の有無を把握する——こうした場面で役立つ画面の一例です。
異常検知アラート画面のイメージ図
需要予測
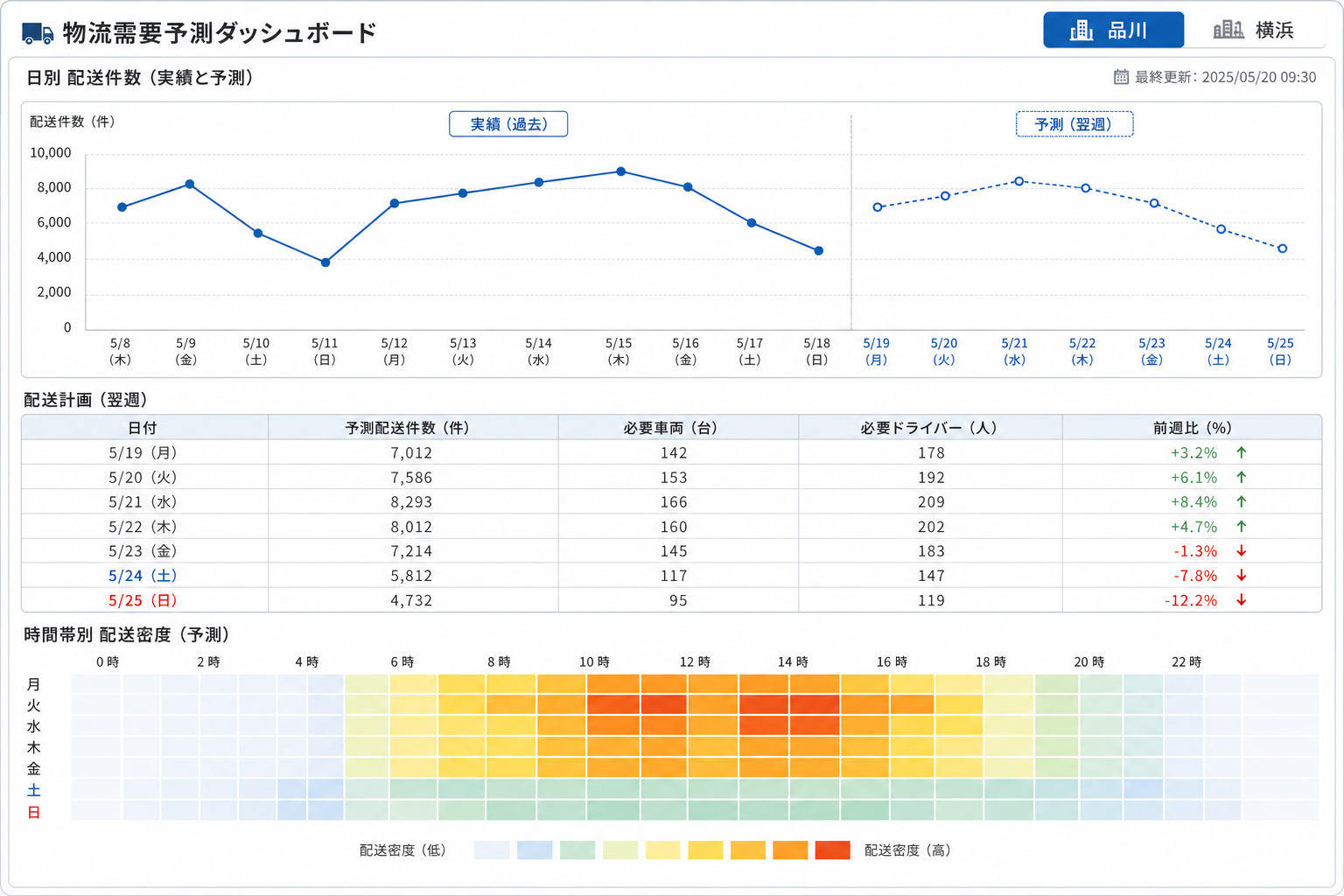
翌日・翌週にどれだけの配送が発生するかを見積もり、車両台数やドライバーのシフトを先回りして組む活用が考えられます。過去の配送件数・曜日・季節の推移を分析し、繁忙期の事前準備に活かす領域です。運行イベントデータと受注データを組み合わせると、「荷役が集中する時間帯」「特定エリアの配送密度」といった現場の負荷パターンも読み取れるようになります。
需要予測では、日別・時間帯別の配送量グラフと、車両・ドライバーの計画表を並べた構成がよく使われる一例です。
※ 以下は画面構成を説明するための想定例です。
| 日付 | 予測配送件数 | 必要車両台数(目安) | 必要ドライバー数(目安) | 前週比 |
|---|---|---|---|---|
| 6/10(火) | 142件 | 8台 | 8名 | +5% |
| 6/11(水) | 138件 | 8台 | 8名 | +3% |
| 6/12(木) | 165件 | 9台 | 9名 | +18% |
グラフで時間帯ごとの荷役集中を帯状に表示し、ピークの時間帯に台数を寄せる計画を立てる際の参考になります。エリア別のタブを切り替えて、品川・横浜など地域ごとの配送密度を確認するイメージです。
需要予測ダッシュボードのイメージ図
データ整備の先に広がる4つの活用領域の関係を、次の概要図にまとめます。
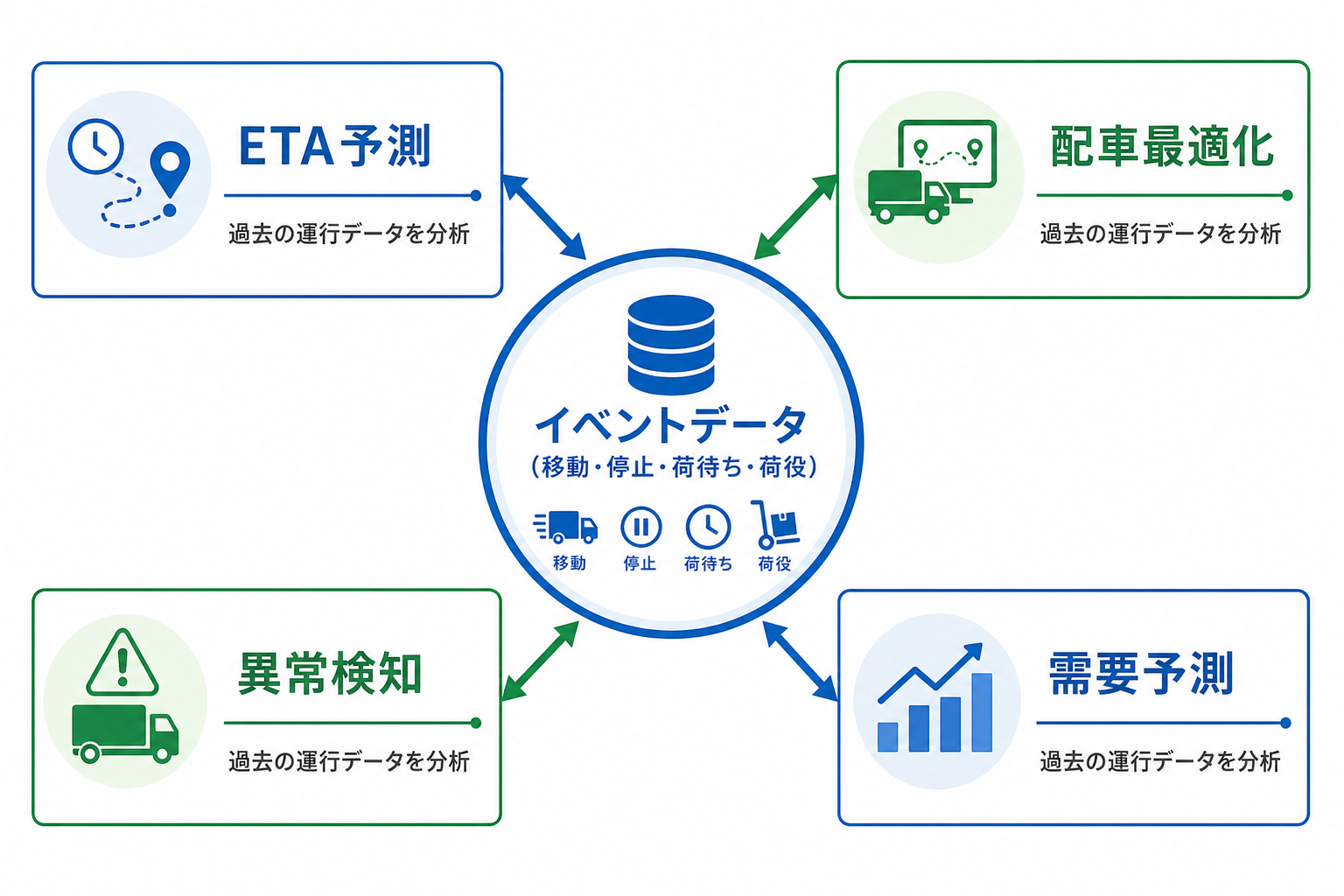
おわりに
データ整備を先に進めると、現場とシステムの会話が変わります。「あの便が遅れている気がする」という感覚的なやり取りから、「荷待ちが25分続いているので次の配送に影響が出る」という根拠のある判断へ移行しやすくなります。
整備されたイベントデータが揃えば、ETA予測の精度検証や配車計画のシミュレーションに同じデータセットを使い回せます。分析のたびに生データを都度加工する手間が減り、改善のサイクルが回りやすくなります。
物流DXの投資判断もしやすくなります。いきなり高度なAIを入れるのではなく、データ基盤構築とイベント変換までを段階的に進めれば、どこまで効果が出たかを区切って確認できます。現場の運用ルールとデータの定義を揃えた状態が、あとから足す分析・最適化の土台になります。